1. 乱序执行
Spectre 攻击依赖于大多数 CPU 实现的一个重要特性。为了理解这一特征,我们来看看以下代码。这段代码检查 x 是否小于 size,如果是,则变量 data 将被更新。假设 size 的值为 10,因此当 x 等于 15 时,第 3 行的代码不会被执行。
1 data = 0;
2 if (x < size) {
3 data = data + 5;
4 }
从 CPU 外部角度来观察这段代码,上述陈述是正确的。然而,如果我们深入到 CPU 的微架构层面查看执行顺序,则会发现即使 x 大于 size,第 3 行也可能被执行。这是因为现代 CPU 采用了一种重要的优化技术,称为乱序执行。乱序执行是一种优化技术,它允许 CPU 最大化利用所有的执行单元。只要指令所需要的数据已经准备好了,CPU 会并行地执行它们,而不是严格按照顺序来执行指令。
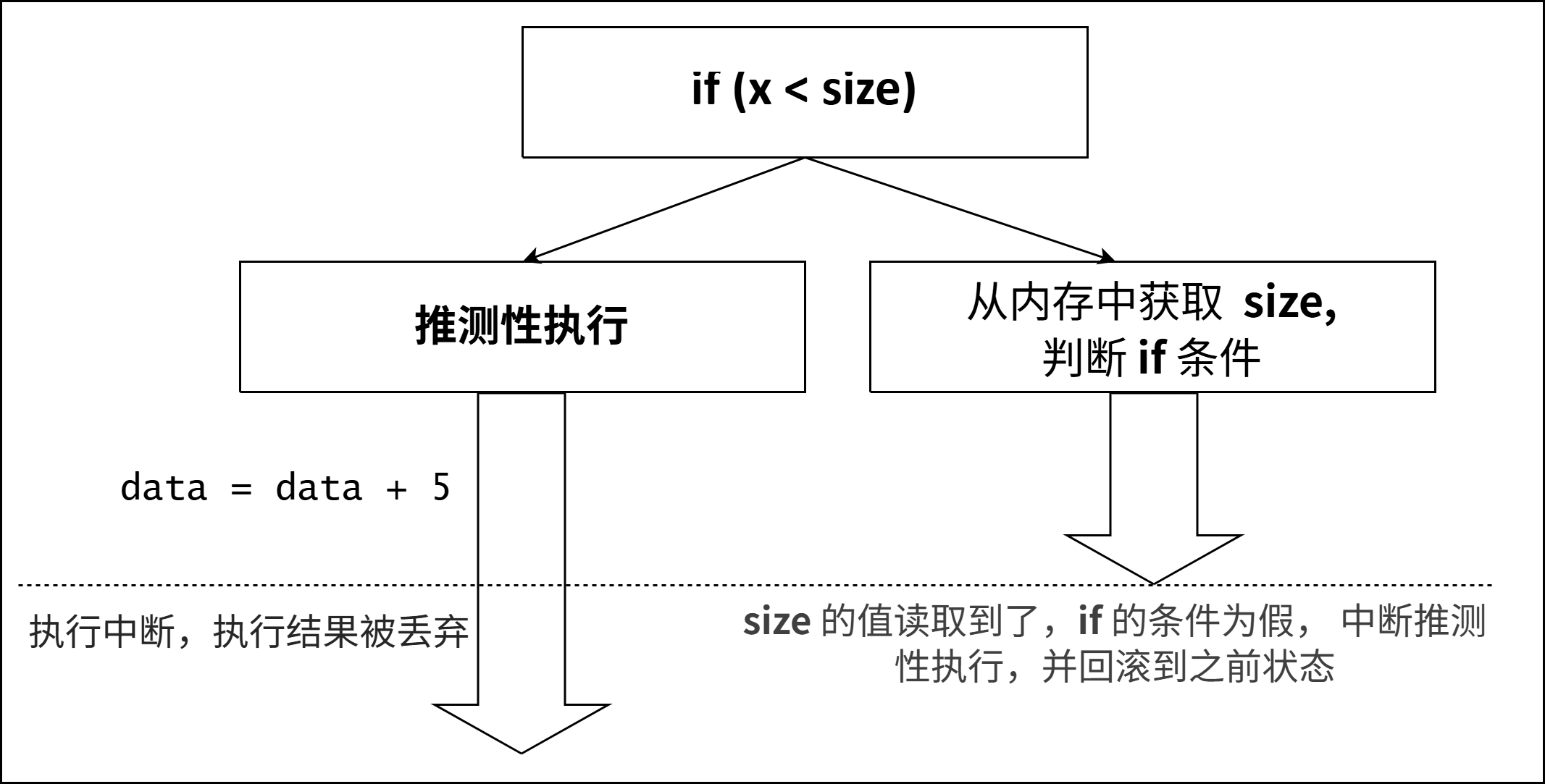
在上述代码示例中,在微架构级别,第 2 行涉及两个操作:从内存加载 size 的值,以及比较该值与 x 的值。如果 size 不在 CPU 缓存中,则可能需要数百个 CPU 时钟周期才能读取其值。现代 CPU 不会闲置地等待比较的结果,而是预测比较的结果,并基于预测来执行相应的分支。由于这种指令的执行没有等前一个指令的结束就开始了,因此被称为乱序执行,在这里,这种乱序执行也叫推测性执行。在进行乱序执行之前,CPU 会存储其当前状态和寄存器的值。当 size 的值最终到达时,CPU 将检查实际结果。如果预测是对的话,则推测性执行的操作会被接受,从而节省了时间。如果预测是错误的,CPU 将恢复到其保存的状态,所有由乱序执行产生的结果都会被丢弃,就好像从未发生过一样。这就是为什么从外部来看,我们是看不到第 3 行被执行了的。下图展示了由于示例代码中的第 2 行引起的乱序执行。
Intel 和其他几家 CPU 制造商在设计乱序执行时犯了一个严重的错误。如果提前执行的指令不应该被执行,那么他们应当清除乱序执行在寄存器和内存的痕迹,因此该执行不会产生任何可见效果。然而,他们忘记了缓存的影响。在乱序执行期间,被使用的内存会被存储在缓存中。如果乱序执行的结果需要被丢弃,则由该执行引起的缓存操作也应该被清除。不幸的是,在大多数 CPU 中并非如此。因此这就会产生可观察的痕迹。使用任务 1 和 2 中的侧信道技术,我们可以观察到这些痕迹。Spectre 攻击巧妙地利用了这种可观测的痕迹来找到受保护的秘密值。
2. 实验
在这个任务中,我们用一个实验来观察由乱序执行引起的效果,所用代码如下所示(SpectreExperiment.c)。
/* SpectreExperiment.c */
#define CACHE_HIT_THRESHOLD (80)
#define DELTA 1024
int size = 10;
uint8_t array[256*4096];
uint8_t temp = 0;
void victim(size_t x)
{
if (x < size) { 🅰
temp = array[x * 4096 + DELTA]; 🅱
}
}
int main()
{
int i;
// 将探测数组的缓存清除
flushSideChannel();
// 训练 CPU 使其在 victim() 中选择正确的分支
for (i = 0; i < 10; i++) { 🅲
victim(i); 🅳
}
// 利用乱序执行
_mm_clflush(&size); ★
for (i = 0; i < 256; i++)
_mm_clflush(&array[i*4096 + DELTA]);
victim(97); 🅴
// 重新加载探测数组
reloadSideChannel();
return (0);
}
为了使 CPU 进行推测性执行,它们需要能够预测 if 条件的结果。CPU 会记录每个分支在过去选择情况,然后用这些历史记录来预测在推测性执行中应选取哪个分支。因此,如果我们希望 CPU 在推测性执行中选取某个特定的分支,我们应当训练 CPU,使得该分支成为预测结果。该训练在第 🅲 行的循环里执行。在循环内部,我们调用 victim() 函数并传递一个较小的参数(从 0 到 9)。这些值都小于 size 的值,因此第 🅰 行当中的 if 条件总是真,条件是真的分支总是被执行。我们通过训练 CPU,来让它在后面的预判中选择条件是真的分支。
一旦 CPU 进行了训练,我们将一个较大的值(97)传递给 victim() 函数(第 🅴 行)。这个值大于 size 的值,所以在实际执行中,if 条件会是假而非为真。然而我们已经清除了内存中的变量 size,因此获取其值需要一些时间。这时 CPU 就会通过预测来推测性执行后面的指令。
任务
请编译上述 SpectreExperiment.c 程序(编译方法见实验环境章节),运行该程序并描述观察结果。由于 CPU 中的一些其他缓存可能会导致侧信道中的噪声,我们稍后会减少这种噪声,但目前我们可以多次运行这个程序来观察效果。当 97 被传递给 victim() 时,观察第 🅱 行是否被执行。请完成以下操作:
- 注释掉标记为 ★ 的行并重新执行一次。解释观察结果。完成后,请不要注释这行,以免影响后续任务。
- 将第 🅳 行替换为 victim(i + 20),重新编译代码并解释观察结果。
 Intel 和其他几家 CPU 制造商在设计乱序执行时犯了一个严重的错误。如果提前执行的指令不应该被执行,那么他们应当清除乱序执行在寄存器和内存的痕迹,因此该执行不会产生任何可见效果。然而,他们忘记了缓存的影响。在乱序执行期间,被使用的内存会被存储在缓存中。如果乱序执行的结果需要被丢弃,则由该执行引起的缓存操作也应该被清除。不幸的是,在大多数 CPU 中并非如此。因此这就会产生可观察的痕迹。使用任务 1 和 2 中的侧信道技术,我们可以观察到这些痕迹。Spectre 攻击巧妙地利用了这种可观测的痕迹来找到受保护的秘密值。
Intel 和其他几家 CPU 制造商在设计乱序执行时犯了一个严重的错误。如果提前执行的指令不应该被执行,那么他们应当清除乱序执行在寄存器和内存的痕迹,因此该执行不会产生任何可见效果。然而,他们忘记了缓存的影响。在乱序执行期间,被使用的内存会被存储在缓存中。如果乱序执行的结果需要被丢弃,则由该执行引起的缓存操作也应该被清除。不幸的是,在大多数 CPU 中并非如此。因此这就会产生可观察的痕迹。使用任务 1 和 2 中的侧信道技术,我们可以观察到这些痕迹。Spectre 攻击巧妙地利用了这种可观测的痕迹来找到受保护的秘密值。