在此任务中,我们提供了下面的 C 程序。你的任务是基于该程序创建两个不同的版本,它们的 xyz 数组的内容不同,但是可执行文件的哈希值却是相同的。
#include <stdio.h>
unsigned char xyz[200] = {
/* The actual contents of this array are up to you */
};
int main()
{
int i;
for (i=0; i<200; i++){
printf("%x", xyz[i]);
}
printf("\n");
}
你可以选择在源代码层面完成这项工作,也就是写两个版本,使得在编译后,它们对应的可执行文件有相同的 MD5 哈希值。但是直接在编译后生成的二进制文件上操作可能会更加简单。你可以在 xyz 数组中放任意的一些数,然后你可以用一个十六进制编辑器来直接在二进制文件中修改 xyz 的内容。找出这个数组存放在二进制文件中的哪个部分并不容易。然而,如果我们在数组中填入一些固定的值,我们就能容易地在二进制文件中找到它们。例如,下面的代码中数组被填满了 0x41 , 即字母 A 的 ASCII 数值。在二进制文件中找到 200 个 A 的位置不会很难。
unsigned char xyz[200] = {
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
... (omitted) ...
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
}
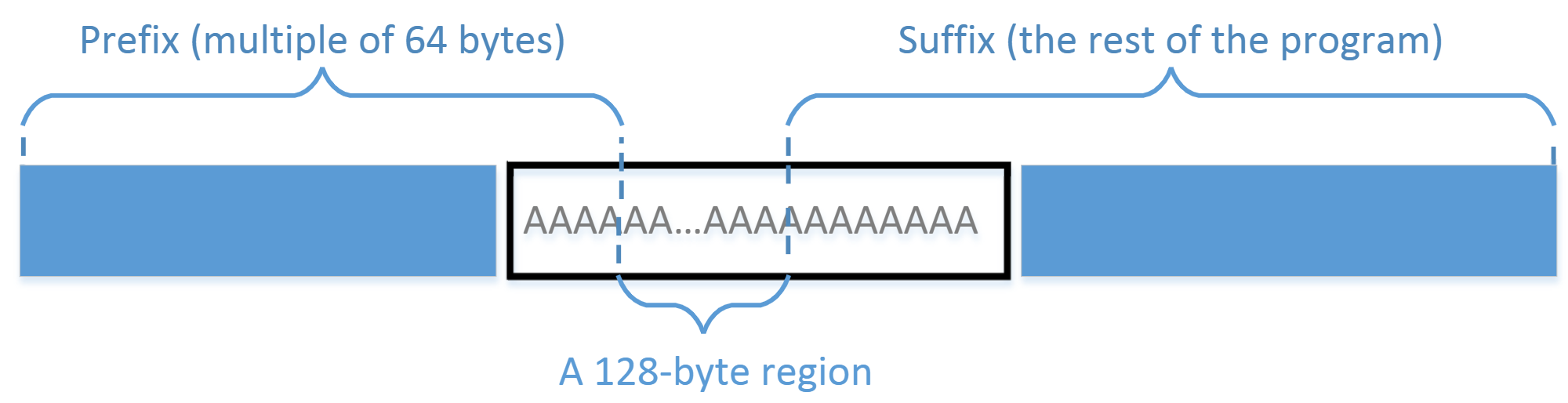
实验指导。在数组内部,我们可以找到两个位置将可执行文件分为三个部分:前缀、 128 字节区域和后缀。前缀的长度必须是 64 个字节的倍数。有关如何分割文件的说明,请参见下图:
我们可以在前缀上运行 md5collgen 生成两个有相同 MD5 哈希值的输出。让我们用 P 和 Q 来表示这些输出的第二个部分(即前缀之后,128 字节的部分)。这样我们就有下面的条件:
MD5 (prefix ‖ P) = MD5 (prefix ‖ Q)
根据 MD5 的性质,我们知道,如果将相同的后缀附加到上述两个输出中,得到的结果也将具有相同的哈希值。下面的结论适用于所有后缀:
MD5 (prefix ‖ P ‖ suffix) = MD5 (prefix ‖ Q ‖ suffix)
因此,我们只需要使用 P 和 Q 替换数组中两个分隔点之间的 128 个字节,然后我们就可以创建两个有相同哈希值的二进制文件。这两个程序的结果是不同的,因为它们分别输出它们自己的数组,而数组有不同的内容。
工具。你可以使用 ghex 工具来查看二进制可执行文件,找到数组的位置。我们有一些工具可以用来在特定的位置分割一个二进制文件。 head 和 tail 命令都是很有用的工具。你可以查看手册来了解如何使用它们。我们在下面给出三个示例:
$ head -c 3200 a.out > prefix
$ tail -c 100 a.out > suffix
$ tail -c +3300 a.out > suffix
第一个命令把 a.out 的前 3200 个字节保存到 prefix 文件中。第二个命令把 a.out 的最后 100 个字节保存到 suffix 文件中。第三个命令把 a.out 从第 3300 个字节到末尾保存到 suffix 中。使用这两个命令,我们可以从任意位置将一个二进制文件分割成几份。如果我们需要把这几部分粘起来,我们可以使用 cat 命令。
 我们可以在前缀上运行 md5collgen 生成两个有相同 MD5 哈希值的输出。让我们用 P 和 Q 来表示这些输出的第二个部分(即前缀之后,128 字节的部分)。这样我们就有下面的条件:
我们可以在前缀上运行 md5collgen 生成两个有相同 MD5 哈希值的输出。让我们用 P 和 Q 来表示这些输出的第二个部分(即前缀之后,128 字节的部分)。这样我们就有下面的条件: