Return-to-libc 攻击实验
章节大纲
-
本实验的学习目标是让大家亲身体验缓冲区溢出攻击的一个有趣的变种, 这种攻击可以绕过目前 Linux 操作系统中实现的保护方案。利用缓冲区溢出漏洞的常见方法是将恶意的 shellcode 注入到被攻击者的栈上, 然后让被攻击的程序跳转到 shellcode。为了防止这类攻击,一些操作系统允许程序将其堆栈设置成不可执行,这样的话,跳转到 shellcode 会导致程序失败。
不幸的是,上述保护方案并非万无一失。存在一种称为 Return-to-libc 的缓冲区溢出攻击变种,它不需要可执行堆栈,甚至不使用 shellcode。相反,它使易受攻击的程序跳转到一些现有代码, 例如进程内存空间中已加载的 libc 库中的 system() 函数。
在这个实验中,你将获得一个具有缓冲区溢出漏洞的程序,你的任务是开发一个 Return-to-libc 攻击来利用这个漏洞, 并最终获得 root 权限。 除了攻击之外,你还将了解 Ubuntu 中实现的一些保护方案,以反击缓冲区溢出攻击。本实验涵盖以下主题:
-
缓冲区溢出漏洞
-
函数调用时的堆栈布局和不可执行堆栈
-
Return-to-libc 攻击和返回导向编程(ROP)
-
-
本实验在 SEEDUbuntu20.04 VM 中测试可行。你可以在本页面右端选择虚拟机版本为 SEEDUbuntu20.04,点击“创建虚拟机”来获取虚拟机平台的临时用户名与密码,登录虚拟机平台即可获得一台预先构建好的 SEEDUbuntu20.04 VM,该虚拟机以及用户名密码将在开启 24 小时后自动销毁。你也可以在其他 VM、物理机器以及云端 VM 上自行配置环境进行实验,但我们不保证实验能在其他 VM 下成功。实验所需的文件可从下方下载,解压后会得到一个名为 Labsetup 的文件夹,该文件夹内包含了完成本实验所需的所有文件。
-
在 Linux 中,当程序运行时,libc 库将被加载到内存中。当内存地址随机化关闭时,对于相同的程序,库总是被加载到相同的内存地址中(对于不同的程序, libc 库的内存地址可能不同)。因此,我们可以使用调试工具,如 gdb,找出 system() 的地址。也就是说,我们可以调试目标程序 retlib。尽管程序是一个 root 拥有的 Set-uid 程序,我们仍然可以调试它,只是权限将被丢弃(即,有效用户 ID 将与真实用户 ID 相同)。在 gdb 中,我们需要输入 run 命令来执行一次目标程序。否则,库代码将不会被加载。我们使用 p 命令(或 print)打印出 system() 和 exit() 函数的地址(我们稍后将需要 exit())。
$ touch badfile $ gdb -q retlib ⬅ 使用"安静"模式 Reading symbols from ./retlib... (No debugging symbols found in ./retlib) gdb-peda$ break main Breakpoint 1 at 0x1327 gdb-peda$ run ...... Breakpoint 1, 0x56556327 in main () gdb-peda$ p system $1 = {<text variable, no debug info>} 0xf7e12420 <system> gdb-peda$ p exit $2 = {<text variable, no debug info>} 0xf7e04f80 <exit> gdb-peda$ quit应当注意,即使对于相同的程序,如果我们将其从 Set-uid 程序更改为非 Set-uid 程序,libc 库可能不会被加载到同一位置。因此,当我们调试程序时,需要调试目标 Set-uid 程序,否则,我们得到的地址可能是错误的。
如果你更喜欢在批处理模式下运行 gdb,你可以将 gdb 命令放入一个文件中,然后让 gdb 执行这个文件中的命令:$ cat gdb_command.txt break main run p system p exit quit $ gdb -q -batch -x gdb_command.txt ./retlib ... Breakpoint 1, 0x56556327 in main () $1 = {<text variable, no debug info>} 0xf7e12420 <system> $2 = {<text variable, no debug info>} 0xf7e04f80 <exit> -
我们的攻击策略是跳转到 system() 函数,并使其执行任意命令。由于我们希望获得 shell 提示符,我们希望 system() 函数执行 "/bin/sh" 程序。因此,命令字符串 "/bin/sh" 必须首先放入内存中,我们必须知道其地址(这个地址需要传递给 system() 函数)。有很多方法可以实现这些目标,我们选择一种使用环境变量的方法。你也可以使用其他方法。当我们从 shell 提示符执行程序时,shell 实际上会生成一个子进程来执行程序,所有被 export 的 shell 变量会成为子进程的环境变量。我们可以通过这个方法将一个任意字符串放入子进程的内存中。让我们定义一个新的 shell 变量 MYSHELL,并让它包含字符串 "/bin/sh"。从以下命令中,我们可以验证字符串进入了子进程,并由在子进程中运行的 env 命令打印出来。
$ export MYSHELL=/bin/sh $ env | grep MYSHELL MYSHELL=/bin/sh我们将使用这个变量的地址作为 system() 调用的参数。这个变量在内存中的位置可以使用以下程序找到:void main(){ char* shell = getenv("MYSHELL"); if (shell) printf("%x\n", (unsigned int)shell); }将上述代码编译成名为 prtenv 的二进制文件。如果关闭了地址随机化,你会发现打印出的是相同的地址。当你在同一终端中运行易受攻击的程序 retlib 时,环境变量的地址将是相同的(见下面的特别说明)。你可以通过将上述代码放入 retlib.c 中来验证这一点。然而,程序名称的长度确实有影响。这就是我们选择 6 个字符作为程序名称 prtenv 以匹配 retlib 的原因。
当你编译上述程序时,应使用 -m32 标志,因为二进制代码 prtenv 是为 32 位机器准备的,而不是 64 位机器。易受攻击的程序 retlib 是一个 32 位二进制文件,所以如果 prtenv 是 64 位的,环境变量的地址将会不同。 -
我们准备创建 badfile 的内容。由于内容涉及二进制数据(例如,libc 函数的地址),我们可以使用 Python 进行构造。我们提供了以下代码框架,关键部分留待你填写。
#!/usr/bin/env python3 import sys # 用非零值填充 content = bytearray(0xaa for i in range(300)) X = 0 sh_addr = 0x00000000 # "/bin/sh" 字符串的地址 content[X:X+4] = (sh_addr).to_bytes(4,byteorder='little') Y = 0 system_addr = 0x00000000 # system() 函数的地址 content[Y:Y+4] = (system_addr).to_bytes(4,byteorder='little') Z = 0 exit_addr = 0x00000000 # exit() 函数的地址 content[Z:Z+4] = (exit_addr).to_bytes(4,byteorder='little') # 保存内容到文件 with open("badfile", "wb") as f: f.write(content)你需要找出三个地址和 X、 Y 和 Z 的值。如果你的值不正确,你的攻击可能不会成功。在你的报告中,你需要描述是如何决定 X、Y 和 Z 的值的,并展示你的推理过程。如果你使用试错方法,展示你的尝试过程。
如果你使用 gdb 来找出 X、Y 和 Z 的值,应当注意到 Ubuntu 20.04 中的 gdb 行为与 Ubuntu 16.04 中的略有不同。在我们设置断点在函数 bof 后,当 gdb 在 bof() 函数内部停止时,它会在 ebp 寄存器设置指向当前堆栈帧之前停止,所以如果我们在这里打印出 ebp 的值,我们将得到调用者的 ebp 值,而不是 bof 的 ebp 。我们需要输入 next 执行一些指令后,在 ebp 寄存器指向 bof() 函数的栈帧后停止。SEED 书(第1版)是基于Ubuntu 16.04,没有这个 next 步骤。同时我们有以下两个问题:
1. 攻击变种1:exit() 函数真的必要吗?请尝试在 badfile 中不包括这个函数的地址,再次运行你的攻击,报告并解释你的观察结果。2. 攻击变种2:在你的攻击成功后,将 retlib 的文件名更改为不同的名称,确保新文件名的长度不同。例如,你可以将其更改为 newretlib。重复攻击(不改变 badfile 的内容)。你的攻击会成功吗?如果没有成功,解释原因。 -
本任务的目的是在启用了 shell 的对策后发起 return-to-libc 攻击。在执行任务 1 至 3 之前,我们将 /bin/sh 重新链接到了 /bin/zsh,而不是 /bin/dash(原始设置)。这是因为一些 shell 程序,如 dash 和 bash,在 Set-UID 进程中执行时会自动放弃权限。在此任务中,我们希望击败此类对策,即即使 /bin/sh 仍然指向 /bin/dash,我们也希望获得 root shell。首先,我们将符号链接改回:
$ sudo ln -sf /bin/dash /bin/sh尽管 dash 和 bash 都会放弃 Set-UID 权限,但如果 -p 选项被调用,权限将不被放弃。当我们返回到 system 函数时,这个函数会调用 /bin/sh ,但它不使用 -p 选项。因此,目标程序的 Set-UID 权限将被放弃。如果有一个函数允许我们直接执行 "/bin/bash -p", 而不是像 system 那样,我们就可以获得 root 权限。
很多 libc 函数都可以做到这一点,例如 exec() 系列函数,包括 execl()、execle()、execv() 等。我们来看 execv() 函数:int execv(const char *pathname, char *const argv[]);这个函数接受两个参数,一个是命令的地址,第二个是命令的参数数组的地址。例如,如果我们想使用 execv 调用 "/bin/bash -p", 我们需要设置如下:pathname = address of "/bin/bash" argv[0] = address of "/bin/bash" argv[1] = address of "-p" argv[2] = NULL (i.e., 4 bytes of zero).从前面的任务中,我们可以轻松获得字符串的地址。因此,如果我们能在堆栈上构造 argv[] 数组,并获取其地址,我们就能进行 return-to-libc 攻击,但这一次,我们将返回到 execv()函数。这里有一个难点。 argv[2] 的值必须是零(一个整数零,四个字节)。如果我们在输入中放入四个零, strcpy() 将在第一个零处终止,任何在它之后的内容都不会被复制到 bof() 函数的缓冲区中。这似乎是一个难题,但请记住,你的输入中的所有内容已经在堆栈上,它们在 main() 函数的缓冲区中。获取这个缓冲区的地址并不难。为了简化任务,我们已让易受攻击的程序为你打印出该地址。就像任务 3 一样,你需要构造你的输入,以便当 bof() 函数返回时,它返回到 execv()。后者从堆栈中获取 "/bin/bash" 字符串的地址和 argv[] 数组的地址。你需要在堆栈上准备好一切,以便当 execv() 被执行时,它可以执行 "/bin/bash -p",从而获得 root shell。在你的报告中,请描述你是如何构造输入的。 -
解决任务 4 中的问题有很多方法。另一种方法是在调用 system() 之前调用 setuid(0)。 setuid(0) 调用将真实用户 ID 和有效用户 ID 都设置为 0,将进程转变为非 Set-UID 进程(它仍然具有 root 权限)。这种方法要求我们将两个函数链接在一起。这种方法被推广为链接多个函数,并且进一步推广为链接多段代码。这就是返回导向编程(ROP)。使用 ROP 解决任务 4 中的问题相当复杂,它超出了本实验的范围。然而,我们希望给大家一个 ROP 的体验,让你们处理 ROP 的一个特例。在 retlib.c 程序中,有一个名为 foo() 的函数,程序中从未被调用。该函数是为本任务准备的。你的任务是利用程序中的缓冲区溢出问题,使得程序从 bof() 函数返回时,调用 foo() 10次,然后给你 root shell。在你的实验报告中,你需要描述你的输入是如何构造的。结果将如下所示:
$ ./retlib ... Function foo() is invoked 1 times Function foo() is invoked 2 times Function foo() is invoked 3 times Function foo() is invoked 4 times Function foo() is invoked 5 times Function foo() is invoked 6 times Function foo() is invoked 7 times Function foo() is invoked 8 times Function foo() is invoked 9 times Function foo() is invoked 10 times bash-5.0# ← Got root shell!让我们回顾一下我们在任务 3 中所做的。我们在堆栈上构造数据,使得当程序从 bof() 返回时,它跳转到 system() 函数,并且当 system() 返回时,程序跳转到 exit() 函数。我们将在这里使用类似的策略。我们不会跳转到 system() 和 exit(),而是在堆栈上构造数据,使得当程序从 bof 返回时,它返回到 foo;当 foo 返回时,它返回到另一个 foo。这个过程重复 10 次。当第 10 个 foo返回时,它返回到 execv() 函数,给我们 root shell。我们在本任务中所做的只是 ROP 的一个特例。你可能已经注意到 foo() 函数不接受任何参数。否则,调用它 10 次将变得更加复杂。通用的 ROP 技术允许你按顺序调用任何数量的函数,允许每个函数有多个参数。SEED书(第 3 版)提供了如何使用通用 ROP 技术解决任务 4 中问题的详细说明。它涉及调用 sprintf() 四次,然后调用 setuid(0),再调用 system("/bin/sh") 给我们 root shell。这种方法相当复杂,SEED 书中用了 15 页的内容来解释。 -
-
-
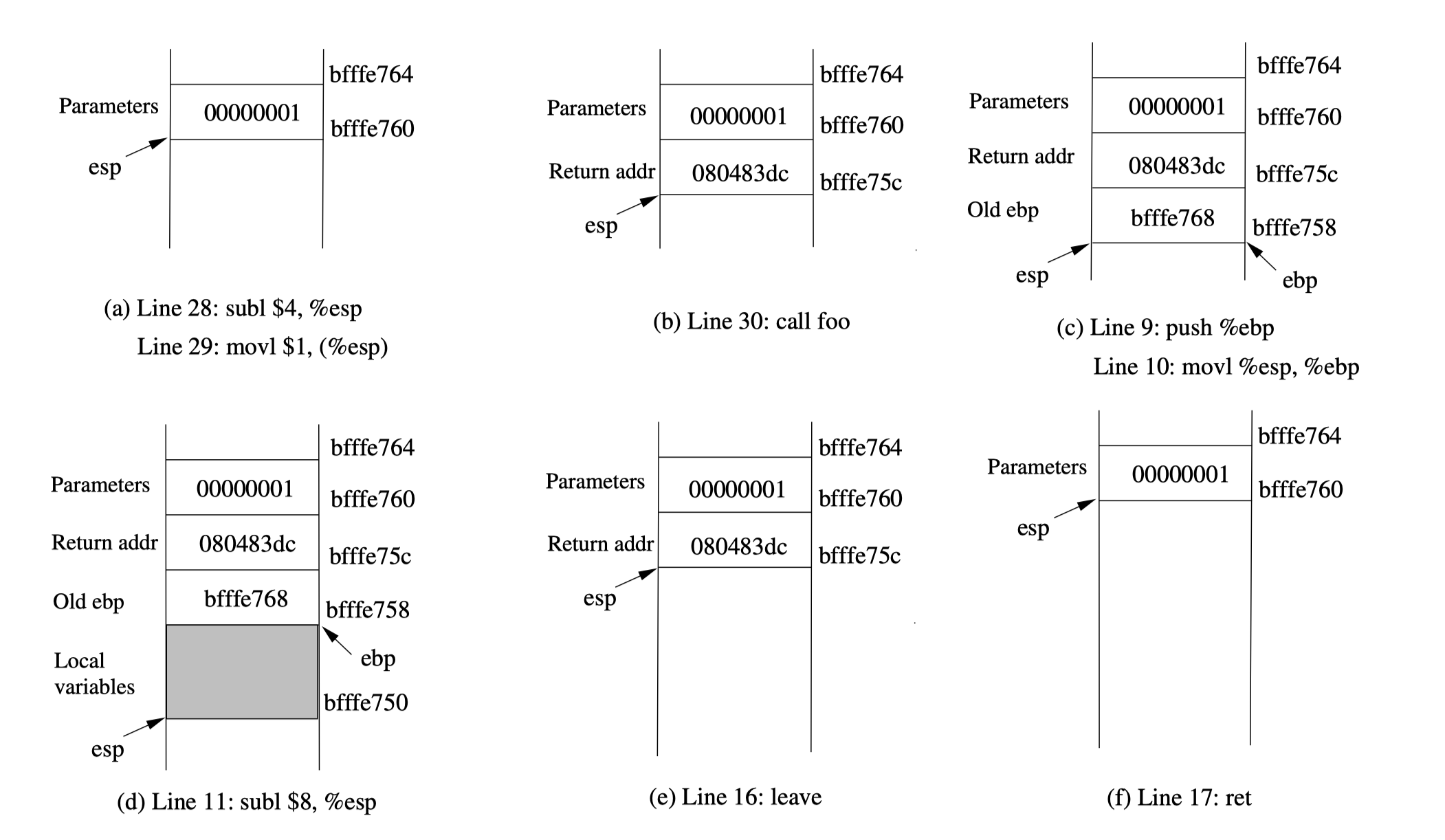
让我们关注调用 foo() 时的堆栈。我们可以忽略之前的堆栈。请注意,本解释中使用的是行号而不是指令地址。
-
第 28-29 行:这两个语句将值 1,即 foo() 的参数,推入堆栈。这个操作使 %esp 增加 4。这两个语句之后的堆栈如图 (a) 所示。
-
第 30 行:call foo:该语句将紧随 call 语句之后的下一条指令的地址推入堆栈(即返回地址)然后跳转到 foo() 的代码。当前堆栈如图 (b) 所示。
-
第 9-10 行:函数 foo() 的第一行将 %ebp 推入堆栈,以保存先前的栈帧指针。第二行让 %ebp 指向当前栈帧。当前堆栈如图 (c) 所示。
-
第 11 行:subl $8, %esp:堆栈指针被修改,以便为局部变量和传递给 printf 的两个参数分配空间(共 8 字节)。 由于函数 foo 中没有局部变量,这 8 字节仅用于参数传递。 见图 (d)。
-
-